数据类型与变量
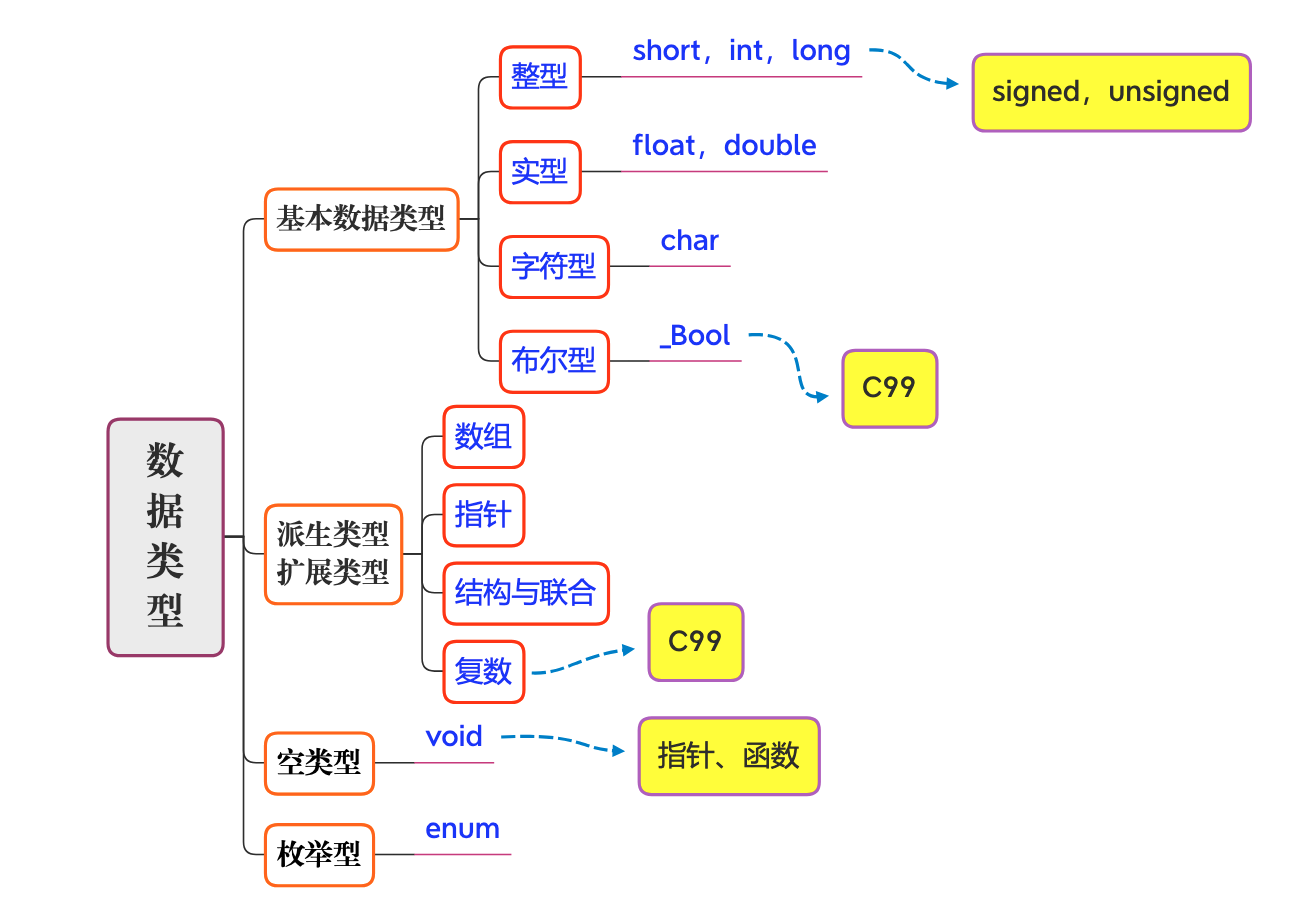
C 语言的数据类型可分为基本数据类型和派生(扩展)数据类型。
- 基本数据类型: 整型, 实型, 字符型(char)和布尔型(_Bool)
- 整型: int, short, long, unsigned int, unsigned short, unsigned long
- 实型: float, double
- 派生(扩展、导出、自定义)数据类型: 数组, 指针, 枚举, 结构, 联合, 复数, 等等
整数类型¶
| 类型 | 存储大小 | 值范围 | 说明 |
|---|---|---|---|
| char | 1 字节 | -128 到 127 或 0 到 255 | 不同系统中char可能是有符号的或者无符号的 |
| unsigned char | 1 字节 | 0 到 255 | |
| signed char | 1 字节 | -128 到 127 | |
| int | 4 字节 | -2,147,483,648 到 2,147,483,647 | 有符号32位整数 |
| unsigned int | 4 字节 | 0 到 4,294,967,295 | |
| short | 2 字节 | -32,768 到 32,767 | 有符号16位整数 |
| unsigned short | 2 字节 | 0 到 65,535 | |
| long(long int) | 4 字节或8 字节 | -2,147,483,648 到 2,147,483,647 | 在32位系统中是32位有符号整数,在64位系统中是64位有符号整数整数 |
| long long(long long int) | 8字节 | 有符号64位整数 | |
| unsigned long | 4 字节 | 0 到 4,294,967,295 | |
| bool | 1 字节 | 0 到 255 | _Bool类型。定义在stdbool.h中定义了bool/true/false宏便于使用 |
| uintptr_t | 4字节 或 8字节 |
[!note] 笔记
- 上面图标中将char和_Bool也放入到整数类型中进行对比
- 事实上, C 语言标准没有规定每种数据类型的具体字节数和表示范围, 只规定大小顺 序, 即长度满足下面的关系式
char <= short <= int <= long <= long long
具体长度由编译器决定.
如果需要精确的整数类型,可以引入stdint.h:
typedef signed char int8_t;
typedef short int int16_t;
typedef int int32_t;
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
#if __WORDSIZE == 64
typedef long int int64_t;
typedef unsigned long int uint64_t;
#else
__extension__
typedef long long int int64_t;
typedef unsigned long long int uint64_t;
#endif
/* Types for `void *' pointers. */
#if __WORDSIZE == 64
typedef unsigned long int uintptr_t;
#else
typedef unsigned int uintptr_t;
#endif
stdint.h中还定义了整数类型的⼤小限制:
# define INT8_MIN (-128)
# define INT16_MIN (-32767-1)
# define INT32_MIN (-2147483647-1)
# define INT64_MIN (-__INT64_C(9223372036854775807)-1)
# define INT8_MAX (127)
# define INT16_MAX (32767)
# define INT32_MAX (2147483647)
# define INT64_MAX (__INT64_C(9223372036854775807))
# define UINT8_MAX (255)
# define UINT16_MAX (65535)
# define UINT32_MAX (4294967295U)
# define UINT64_MAX (__UINT64_C(18446744073709551615))
我们可以⽤用不同的后缀来表⽰整数常量类型。
85 /* 十进制 */
0213 /* 八进制 */
0x4b /* 十六进制 */
30 /* 整数 */
30u /* 无符号整数 */
30l /* 长整数 */
30ul /* 无符号长整数 */
printf("int size=%d;\\n", sizeof(1));
printf("unsigned int size=%d;\\n", sizeof(1U));
printf("long size=%d;\\n", sizeof(1L));
printf("unsigned long size=%d;\\n", sizeof(1UL));
printf("long long size=%d;\\n", sizeof(1LL));
printf("unsigned long long size=%d;\\n", sizeof(1ULL));
上面输出:
int size=4;
unsigned int size=4;
long size=4;
unsigned long size=4;
long long size=8;
unsigned long long size=8;
字符char¶
字符是C语言中的一种基本数据类型,用于存储单个字符,占用1个字节(8位)。
[!warning] 注意 由于在不同系统上
char可能代表有符号或⽆无符号8位整数,因此建议使⽤unsigned char/signed char来表⽰示具体的类型。
字符与字符字面量¶
字符和字符字面量(也叫字符常量,比如'A'就是一个字符字面量)是两个相关但不同的概念。字符字面量是直接在代码中表示的字符值,用单引号括起来,它的类型是int,而不是char。字符字面量在存储时会被转换为整数类型。
上面输出:
字符参加算术运算时, 自动转换为整数 (按 ASCII 码转换):
通过字符算术运算操作,我们可以是实现ASCII字母的大小转换,转换原理如下:
- 大写字母范围:
A(65) 到Z(90) - 小写字母范围:
a(97) 到z(122) - 大小写字母差值:
32(例如A→a是65 + 32 = 97)
char to_lower(char c) {
if (c >= 'A' && c <= 'Z') {
return c + 32; // 大写转小写
}
return c;
}
char to_upper(char c) {
if (c >= 'a' && c <= 'z') {
return c - 32; // 小写转大写
}
return c;
}
uintptr_t¶
指针是个有特殊⽤用途的整数,在stdint.h中同样给出了其类型定义。
/* Types for `void *' pointers. */
#if __WORDSIZE == 64
typedef unsigned long int uintptr_t;
#else
typedef unsigned int uintptr_t;
#endif
浮点类型¶
浮点类型也称为实型。
| 类型 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|
| float | 4 字节 | 1.2E-38 到 3.4E+38 | 6 |
| double | 8 字节 | 2.3E-308 到 1.7E+308 | 15 |
| long double | 16 字节 | 3.4E-4932 到 1.1E+4932 | 19 |
浮点数在计算机中是按照IEEE 754标准存储的,分为以下部分:
-
符号位:表示数值的正负。
-
指数位:表示数值的指数部分。
-
尾数位:表示数值的小数部分。
浮点数默认类型是 double,可以添加后缀 F 来表⽰示 float,L 表⽰示 long double,可以局部省略。
printf("float %f size=%d\\n", 1.F, sizeof(1.F));
printf("double %f size=%d\\n", .123, sizeof(.123));
printf("long double %Lf size=%d\\n", 1.234L, sizeof(1.234L));
输出:
枚举类型¶
枚举类型(Enumeration) 是一种用户定义的数据类型,用于定义一组命名的整数常量。枚举类型提供了一种清晰、可读的方式来表示一组相关的整数值,使代码更具可读性和可维护性。
枚举类型通过enum关键字定义,语法如下:
枚举类型特性:
- 枚举值默认从
0开始,依次递增1。
- 可以为枚举值指定具体的整数值。
- 枚举成员的值可以相同。
- 枚举变量只能存储枚举值。
- 定义枚举类型时候,可以省略枚举名 我们可以通过这种方式来来代替宏定义常量。
enum Color {
RED, // 值为0
GREEN, // 值为1
BLUE // 值为2
};
printf("red = %d\n", RED);
printf("green = %d\n", GREEN);
printf("black = %d\n", BLACK);
复数¶
复数是一种特殊的数据类型,用于表示复数(即包含实部和虚部的数)。C语言在C99标准中引入了对复数的支持,通过<complex.h>头文件提供了复数的定义和操作函数。
C语言中使用_Complex关键字定义复数。复数字面量使用I表示虚部,例如3.0 + 4.0*I表示复数3 + 4i。
# 定义
float _Complex z1; // 单精度复数
double _Complex z2; // 双精度复数
long double _Complex z3; // 扩展精度复数
# 初始化
double _Complex z = 3.0 + 4.0*I; // 初始化复数
# 运算 - 加法
double _Complex z1 = 1.0 + 2.0*I;
double _Complex z2 = 3.0 + 4.0*I;
double _Complex sum = z1 + z2; // 结果为4.0 + 6.0*I
我们可以引入include <complex.h>使用complex来美化_Complex:
别名¶
别名 是一种为现有类型或标识符提供新名称的机制。别名可以提高代码的可读性和可维护性,特别是在处理复杂类型或自定义类型时。
别名机制,用于为现有类型定义新的名称。它不会创建新的类型,只是为现有类型提供一个别名。
示例:
typedef int Integer; // Integer 是 int 的别名
typedef unsigned long ulong; // ulong 是 unsigned long 的别名
typedef struct {
int x;
int y;
} Point; // Point 是结构体的别名
typedef _Bool bool; // bool 是 _Bool 的别名
typedef unsigned int size_t; // size_t 是 unsigned int 类型别名
typedef int int_array[6];// int_array 是 int[6]的别名
typedef int *int_p;// int_p 是 int*的别名
typedef void (*callback_t)(char*,int); // callback_t 是一个函数指针
typedef unsigned char BYTE; // 为unsigned char取名BYTE
[!note] 笔记 标识符(dentifier)是用来标识实体的符号,如变量、常量、函数、类型、属性名称等。 关键字 (keyword) 是为编译器保留,在词法中有特殊含义的标记,不能用作标识符。
与#define区别¶
和 #define 预处理文本替换不同, typedef 是编译器针对具体类型操作。
int main(void)
{
#define string char *
string a, b;// char* a, b; ==> char *a, char b
static_assert(sizeof(a) == 8);
static_assert(sizeof(b) == 1);
return 0;
}
int main(void)
{
typedef char *string;
string a, b;// char *a, char *b;
static_assert(sizeof(a)== 8);
static_assert(sizeof(b) == 8);
return 0;
}
void 类型¶
void 类型指定没有可用的值。它通常用于以下三种情况下:
-
函数返回为空
C 中有各种函数都不返回值,或者您可以说它们返回空。不返回值的函数的返回类型为空。例如 void exit (int status);
-
函数参数为空
C 中有各种函数不接受任何参数。不带参数的函数可以接受一个 void。例如 int rand(void);
-
指针指向 void
类型为 void * 的指针代表对象的地址,而不是类型。例如,内存分配函数
void *malloc( size_t size );返回指向 void 的指针,可以转换为任何数据类型。
结构体¶
^137d26
在C语言中,结构体(Struct) 是一种用户定义的复合数据类型,允许将不同类型的数据组合在一起,形成一个逻辑单元。结构体可以包含多个成员(也称为字段),每个成员可以是不同的数据类型。
定义¶
示例:
初始化¶
// 声明一个结构体(会进行隐式初始化)
// 若stu1是全局变量,那么所有字段都会被自动初始化为它们的零值
// 若stu1是局部变量,那么所有字段的值都是未定义的
struct Student stu1
// 初始化结构体
struct Student stu2 = {"Alice", 18, 90.5};
// 逐成员赋值
struct Student stu3;
strcpy(stu2.name, "Bob");
stu2.age = 19;
stu2.score = 85.0;
// 动态初始化
struct Student *stu4 = &(struct Student){"Charlie", 20, 95.5};
访问成员变量¶
直接访问¶
结构体变量可以通过点运算符(.)直接访问结构体的成员。
指针访问¶
对于指向结构体变量的指针,我们可以使用箭头运算符(->)访问结构体的成员。
结构体数组¶
struct Student class[3] = {
{"Alice", 18, 90.5},
{"Bob", 19, 85.0},
{"Charlie", 20, 95.5}
};
// 遍历结构体数组
for (int i = 0; i < 3; i++) {
printf("%s的年龄:%d\n", class[i].name, class[i].age);
}
嵌套结构体¶
struct Address {
char city[20];
char street[50];
};
struct Employee {
char name[20];
int id;
struct Address addr; // 嵌套结构体
};
// 初始化
struct Employee emp = {
"David", 1001,
{"Shanghai", "Nanjing Road"}
};
使用typedef简化结构体¶
我们可以使用使用 typedef 创建结构体别名来简化结构体使用:
typedef struct Student {
char name[20];
int age;
} Student; // 别名
// 声明变量
Student stu5 = {"Frank", 22, 88.0};
对于对于包含指向自身指针的结构体(称为自引用结构体),需结合标签和typedef进行定义:
typedef struct Node {
int data;
struct Node *next; // 必须用 struct Node(此时别名未生效)
} Node; // 别名 Node 在定义后才生效
// 后续使用别名
Node *head = NULL;
位字段¶
在C语言中,位字段(Bit-field) 是一种允许程序员指定变量存储位数的方式,通常用于结构体中。通过位字段,可以精确控制变量在内存中的存储位数,从而优化内存使用。位字段常用于硬件编程和需要精细控制内存的场景。
由于是把结构体或联合体的多个成员 "压缩存储" 在一个字段中,所以我们不能对某个位字段成员使⽤ offsetof,当然也不能取地址操作。
int main() {
struct
{
unsigned int year : 22;
unsigned int month : 4;
unsigned int day : 6;
} date = { 2010, 4, 30 };
printf("size: %ld\n", sizeof(date));
printf("year = %u, month = %u, day = %u\n", date.year, date.month, date.day);
}
我们可以使用位字段来做标志位,⽐用位移运算符更直观,更节省内存。
int main() {
struct
{
bool a: 1;
bool b: 1;
bool c: 1;
} flags = { .b = true };
printf("%s\n", flags.b ? "b.T" : "b.F");
printf("%s\n", flags.c ? "c.T" : "c.F");
}
弹性结构成员¶
通常称作 “不定⻓结构”或零长数组结构,就是在结构体尾部声明⼀一个未指定⻓长度的数组。用 sizeof 运算符时,该数组未计⼊入结果。考虑到不同编译器和 ANSI C 标准的问题,也⽤用 char chars[1] 或 char chars[0] 来代替。对这类结构体进行拷贝的时候,尾部结构成员不会被复制,而且不能直接对弹性成员进⾏行初始化。
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct string
{
int length;
char chars[];
} string;
int main(int argc, char * argv[])
{
int len = sizeof(string) + 10; // 计算存储⼀一个 10 字节⻓长度的字符串(包括 \0)所需的⻓长度。
char buf[len]; // 从栈上分配所需的内存空间。
string *s = (string*)buf; // 转换成 struct string 指针。
s->length = 9;
strcpy(s->chars, "123456");
printf("%d: %s\n", s->length, s->chars); // 输出9:123456
string s2 = *s;
printf("%d: %s\n", s2.length, s2.chars); // 输出9:
return EXIT_SUCCESS;
}
内存对齐¶
编译器根据成员类型自动插入填充字节,优化内存访问速度(工作原理是避免flase-share)。我们可以通过 #pragma pack(n) 指定对齐字节数(n通常为1, 2, 4, 8)。
#pragma pack(1) // 1字节对齐(取消填充)
struct PackedData {
char a; // 1字节
int b; // 4字节
}; // 总大小=5字节(默认对齐时为8字节)
#pragma pack() // 恢复默认对齐
结构体使用常见错误与规避¶
- 未初始化指针(野指针)
- 内存泄漏
- 浅拷贝导致数据共享
typedef struct {
char *name; // 指针成员
int age;
} Person;
Person p1;
p1.name = malloc(10);
strcpy(p1.name, "Alice");
Person p2 = p1; // 浅拷贝:p2.name 和 p1.name 指向同一内存
free(p1.name); // p2.name 变为悬空指针!
修复代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char *name;
int age;
} Person;
int main() {
// 修复错误1:正确初始化指针
Person *p1 = malloc(sizeof(Person));
if (p1 == NULL) return -1;
p1->name = strdup("Alice"); // strdup内部自动malloc
p1->age = 25;
// 修复错误3:深拷贝
Person p2;
p2.name = malloc(strlen(p1->name) + 1);
if (p2.name != NULL) {
strcpy(p2.name, p1->name);
}
p2.age = p1->age;
// 修复错误2:释放内存
free(p1->name);
free(p1);
p1 = NULL;
printf("p2: %s, %d\n", p2.name, p2.age);
free(p2.name); // 深拷贝的name也需要释放
return 0;
}
联合体¶
在C语言中,联合体(Union) 是一种用户定义的复合数据类型,允许在同一个内存位置存储不同类型的数据。联合体的所有成员共享同一块内存空间,因此联合体的大小等于其最大成员的大小。
定义¶
示例:
联合体的内存共享¶
#include <stdio.h>
union Data {
int i;
float f;
char c;
};
int main() {
union Data d;
d.i = 65; // ASCII码65对应字符'A'
printf("As integer: %d\n", d.i); // 输出65
printf("As character: %c\n", d.c); // 输出'A'
d.f = 65.0f;
printf("As float: %.2f\n", d.f); // 输出65.00
printf("As integer: %d\n", d.i); // 输出65(可能因浮点表示而不同)
return 0;
}
我们可以使用使用联合体判断系统端序。
#include <stdio.h>
union EndianTest {
int i;
char c[sizeof(int)];
};
int main() {
union EndianTest et;
et.i = 1;
if (et.c[0] == 1) {
printf("Little-endian\n");
} else {
printf("Big-endian\n");
}
return 0;
}
字节序¶
主机字节序(Host Byte Order)¶
主机字节序也叫做系统端序,指的是数据在本地计算机内存中存储的顺序。不同的计算机架构可能使用不同的字节序:
- 小端字节序(Little-endian):低位字节在前,高位字节在后。例如,Intel x86架构。
- 大端字节序(Big-endian):高位字节在前,低位字节在后。例如,Motorola 68000架构。
我们可以通过下面命令查看系统端序:
#include <stdio.h>
int main() {
int num = 0x12345678;
unsigned char *ptr = (unsigned char *)#
if (ptr[0] == 0x78) {
printf("Little Endian\n");
} else if (ptr[0] == 0x12) {
printf("Big Endian\n");
}
return 0;
}
网络字节序(Network Byte Order)¶
网络字节序是网络通信中统一使用的字节序,以确保不同主机之间传输的数据能够被正确解释。网络字节序规定使用大端字节序。
假设你有一个16位的整数0x1234,在小端字节序的系统中:
在网络字节序中,它应该按照0x12 -> 0x34这个顺序发送:
#include <arpa/inet.h>
#include <stdint.h>
#include <stdio.h>
int main() {
uint16_t value = 0x1234; // 本地字节序(小端序:0x34, 0x12)
uint16_t net_value = htons(value); // 转换为网络字节序(0x12, 0x34)
// 拆分为字节
uint8_t buffer[2];
buffer[0] = (net_value >> 8) & 0xFF; // 高位字节:0x12
buffer[1] = net_value & 0xFF; // 低位字节:0x34
printf("Send order: %02x %02x\n", buffer[0], buffer[1]); // 0x12 0x34
return 0;
}
当接收方收到发送过来的0x1234时候,若是接收方是大端序,那么正好满足要求,因为此时高位0x12在低字节,0x34在高字节,不用再调整。若接收方是小端序,那就需要ntohs进行处理。
联合每次只能存储⼀一个成员,联合的⻓长度由最宽成员类型决定。
#include <stdio.h>
#include <stddef.h>
#include <string.h>
typedef struct {
int type;
union {
int ivalue;
long long lvalue;
} value;
} data_t;
int main() {
// 查看联合体大小,value长度由最宽的成员lvalue决定,所以data_t大小是16
printf("Size of data_t: %zu\n", sizeof(data_t)); // 16
printf("Offset of type: %zu\n", offsetof(data_t, type)); // 0
printf("Offset of ivalue: %zu\n", offsetof(data_t, value.ivalue)); // 8
printf("Offset of lvalue: %zu\n", offsetof(data_t, value.lvalue)); // 8
data_t d1 = {.type=1, .value.lvalue=100};
printf("%d %lld\n", d1.type, d1.value.lvalue); // 1 100
data_t d2;
memcpy(&d2, &d1, sizeof(d1)); // 复制联合体
printf("%d %lld\n", d1.type, d1.value.lvalue); // 1 100
union { int x; struct {char a, b, c, d;} bytes; } n = { 0x12345678 };
printf("%#x => %x, %x, %x, %x\n", n.x, n.bytes.a, n.bytes.b, n.bytes.c, n.bytes.d); // 0x12345678 => 78, 56, 34, 12
return 0;
}
可以使⽤用初始化器初始化联合,如果没有指定成员修饰符,则默认是第⼀一个成员。
union value_t
{
int ivalue;
long long lvalue;
};
union value_t v1 = { 10 };
printf("%d\n", v1.ivalue);
union value_t v2 = { .lvalue = 20LL };
printf("%lld\n", v2.lvalue);
union value2_t { char c; int x; } v3 = { .x = 100 };
printf("%d\n", v3.x);
数据类型转换¶
C语言中的类型转换规则可分为隐式转换和显式转换两类。
隐式类型转换(自动转换)¶
整型提升(Integer Promotion)¶
-
在表达式中,
char、short等小于int的整型(包括有符号和无符号)会被自动提升为int或unsigned int,以便参与运算。例如:
通常算术转换(Usual Arithmetic Conversions)¶
当操作数类型不同时,按以下顺序转换:
-
浮点优先:若存在浮点类型,向更高精度的浮点类型转换:
float → double → long double。 -
整数转换:若均为整数类型,按等级提升方向转换(有符号与无符号混合时需注意):
- 等级顺序(从低到高):
_Bool → char → short → int → long → long long。 -
若带符号类型与无符号类型混合:
- 若无符号类型等级≥带符号类型,带符号转为无符号。
- 否则,若带符号类型能表示无符号类型所有值,无符号转为带符号;否则,两者转为无符号类型对应的更高等级类型。
-
赋值转换
右侧表达式的值自动转换为左侧变量的类型,可能发生截断或精度丢失:
- 函数调用转换
- 若函数原型已声明,参数类型自动转换为声明类型。
- 若未声明,参数按默认提升规则转换:
char、short提升为int;float提升为double。
显式类型转换(强制转换)¶
通过强制运算符(type)显式指定目标类型:
- 注意事项:
- 可能丢失数据(如浮点转整数丢弃小数部分)。
- 指针强制转换需谨慎,可能引发未定义行为。
关键注意事项¶
- 符号问题
混合有符号和无符号类型时,负数可能被转为极大正数,导致逻辑错误:
- 精度丢失
- 大整数转浮点数可能损失精度(如
int转float)。 -
浮点数转整数时直接截断小数部分。
-
指针转换
void*可隐式转换为其他指针类型,但反向需强制转换。- 不同类型指针的强制转换可能导致未定义行为(如
int*转float*后解引用)。
示例:
int a = 10;
double b = 3.14;
float c = a + b; // a转double→结果转float
unsigned d = -1; // d = UINT_MAX
char e = 500; // 溢出(假设char为8位,值为244或未定义)
int f = (int)b; // f = 3(显式截断)
以下是C语言类型转换规则的简化表格总结:
C语言类型转换规则表
| 转换类型 | 规则描述 | 示例 | 注意事项 |
|---|---|---|---|
| 隐式转换 | |||
| 整型提升 | char、short等小整型自动提升为int或unsigned int参与运算。 |
char a=10, b=20; int c = a + b; → a和b转为int计算。 |
提升后的结果可能超出原类型范围。 |
| 算术转换 | 不同类型混合运算时,按以下优先级转换: 1. 浮点型 > 整型 2. 精度/等级更高者优先。 (具体规则见下文) |
int + float → floatint + unsigned int → unsigned int |
混合有符号和无符号类型时,可能引发符号错误(如负数转为极大正数)。 |
| 赋值转换 | 右侧值自动转为左侧变量类型(可能截断或溢出)。 | int a=3.14; → a=3unsigned c=-1; → c=UINT_MAX |
浮点转整数会截断小数;溢出时结果依赖类型(如无符号数按模运算)。 |
| 函数参数传递 | 若未声明函数原型,char、short转int;float转double。 |
调用void func(int);时传入char → 自动转为int。 |
未声明原型的函数调用可能导致意外类型转换。 |
| 显式转换 | |||
| 强制转换 | 使用(type)显式指定目标类型。 |
double x=3.14; int y=(int)x; → y=3 |
指针强制转换需谨慎(如int*转float*后解引用可能未定义)。 |
算术转换详细规则(混合类型运算)
| 操作数类型 | 转换方向 |
|---|---|
含long double |
另一个操作数转为long double |
含double |
另一个操作数转为double |
含float |
另一个操作数转为float |
| 均为整型(有/无符号混合) | 按等级提升,且优先转为无符号类型(若等级≥有符号类型),否则可能转为更宽类型。 |
变量¶
^07939e
变量是程序中用于存储数据的内存位置的名称。变量的值可以在程序运行过程中被修改。变量具有下面特点:
- 变量必须先声明,后使用。
- 变量的类型决定了它可以存储的数据类型。
- 变量的值可以动态改变。
定义与声明¶
定义¶
定义(define)是指给变量分配内存空间并初始化值。语法如下: ^cb3d83
声明¶
^600532
声明(declare)是仅告知编译器变量的存在和类型,不分配内存。使用 extern 关键字声明外部变量(定义在其他文件中)。
[!warning] 注意 一个变量可以被声明多次,但只能被定义一次。
作用域¶
作用域(Scope)决定了变量或函数在程序中的可见性(Visibility)和可访问性范围(Scope),通常由代码块、函数或文件的边界定义。
| 作用域类型 | 范围 | 示例 |
|---|---|---|
| 块作用域 | 在 {} 内定义的变量(如函数、循环内部)。该变量是局部变量。 |
{ int x = 5; } // x只在{}内有效 |
| 文件作用域 | 在函数外定义的变量(全局变量)。 | int global = 100; // 全局变量 |
| 函数原型作用域 | 函数参数声明的作用域(仅限原型内)。 | void func(int param); // param仅在原型中有效 |
局部变量¶
局部变量:数据只在某个局部区域内有效(可见), 如:
- 函数的形参和函数中定义的变量,只在该函数内有效
- for 循环初始语句中定义的变量和循环体内定义的变量,只在循环内有效
- 语句块中定义的变量只在该语句块中有效

全局变量¶
全局变量在整个程序中都有效(可见)。
- 全局变量需在所有函数外定义,在它后面定义的函数中均可以使用。
- 若要在它前面定义的函数中使用该全局变量,则需声明其为外部变量:
extern 数据类型名 变量名
- 若局部变量与全局变量同名,则优先使用局部变量
#include <stdio.h>
int k = 2; // 全局变量
int main()
{
int i=5, x; // 局部变量
x=i+k;
printf("x=%d\n", x);
{
int k=16; // 局部变量
x=i+k;
printf("x=%d\n", x);
}
x=i+k;
printf("x=%d\n", x);
}
[!note] 笔记
- 对于全局变量和静态变量(在函数内部定义的静态变量和在函数外部定义的全局变量),它们的默认初始值为0。
- 字符型变量的默认值为 \0。
- 指针变量的默认值为 NULL。
- 局部变量没有默认值,其初始值是未定义的。
生命周期¶
生命周期(Lifetime)指的是变量或对象在程序运行过程中存在的时间段,从创建到销毁的整个过程。
| 存储类别 | 生命周期 | 示例 |
|---|---|---|
| 自动存储期 | 变量在进入块时分配,退出块时释放。 | void func() { int a; } // a在func()调用时创建,返回时销毁 |
| 静态存储期 | 变量在程序启动时分配,结束时释放。 | static int s = 0; // s在程序运行期间始终存在 |
| 动态存储期 | 由 malloc/free 手动管理(堆内存)。 |
int *p = malloc(sizeof(int)); // p指向堆内存 |
类型修饰符¶
类型修饰符(也称类型限定符(Type Qualifiers)) 是用于修改基本数据类型的存储方式、取值范围或行为的关键词。类型修饰符通常与基本数据类型一起使用,以扩展或限制其功能。
const¶
const限定符1用于声明对象为只读(不可修改)。主要用途是:
- 保护数据不被意外修改(如函数参数、全局常量)。
- 优化编译器对常量表达式的处理。
const int MAX = 100; // 常量,不可修改
const int *p = &MAX; // 指向常量的指针(指针可变,指向的值不可变)
int *const q = &x; // 常量指针(指针不可变,指向的值可变)
volatile¶
用于告诉编译器不要对变量的访问进行某些优化(如缓存到寄存器),因为该变量的值可能在编译器无法预知的时机被外部因素修改。volatile 确保编译器:
- 每次访问变量时都直接从内存读取,而不是使用寄存器中的缓存值。
- 每次写入变量时都直接写到内存,而不是延迟或优化掉写操作。
- 不对变量访问的顺序进行重排(在编译器优化时)。
volatile 适用的主要场景有:
硬件寄存器访问(嵌入式系统)
- 场景:在嵌入式开发中,程序直接操作硬件寄存器(如GPIO、定时器或中断控制器的寄存器)。这些寄存器的值可能由硬件异步修改,编译器无法预测。
- 问题:如果没有
volatile,编译器可能优化掉对寄存器的重复读写,认为值未改变,导致程序逻辑错误。 -
示例:
volatile uint32_t * const status_reg = (uint32_t *)0x40008000; // 硬件状态寄存器 while (*status_reg & 0x1) { // 轮询硬件状态 // 等待硬件标志位清零 }这里,
volatile确保每次循环都从硬件寄存器地址读取最新值,而不是使用缓存的旧值。 - 适用性:嵌入式系统、驱动开发或直接操作内存映射的硬件接口。
信号处理程序(Signal Handling)
- 场景:在信号处理程序中修改的全局变量,可能被主程序或其他上下文访问。
- 问题:编译器可能假设变量未被信号处理程序修改,从而优化掉读操作,导致主程序无法感知变量的变化。
-
示例:
volatile int signal_received = 0; void signal_handler(int sig) { signal_received = 1; // 信号处理程序修改 } int main() { signal(SIGINT, signal_handler); while (!signal_received) { // 等待信号 } printf("Signal received!\n"); return 0; }volatile确保主程序的while循环每次都检查signal_received的最新值。 - 适用性:信号处理、异步事件处理。
多线程共享变量(无锁或弱同步场景)
- 场景:在多线程程序中,共享变量在没有锁或原子操作保护的情况下被访问,且需要确保内存可见性。
- 问题:编译器可能优化变量访问,导致线程读取到过期的值。
volatile确保每次访问都直接操作内存,但不保证原子性或线程安全。 -
示例:
volatile int flag = 0; // 共享标志 void *thread1(void *arg) { flag = 1; // 通知线程2 return NULL; } void *thread2(void *arg) { while (!flag) { // 等待线程1设置标志 // 空循环 } printf("Flag set!\n"); return NULL; }这里,
volatile确保线程2每次检查flag时读取内存中的最新值,而不是寄存器中的旧值。 - 注意:volatile不解决数据竞争问题(如多个线程同时写)。如果需要线程安全,应使用互斥锁(如你的代码中的pthread_mutex_t)或 C11 的_Atomic类型。 - 适用性:极少数无锁编程场景,或调试多线程问题时临时使用。通常更推荐使用锁或原子操作。
内存映射的I/O或设备驱动
- 场景:在设备驱动程序中,访问内存映射的I/O区域(如DMA缓冲区、共享内存)。
- 问题:这些区域的值可能由外部设备修改,编译器优化可能导致错误。
-
示例:
volatile char * const buffer = (char *)0x10000000; // 内存映射的设备缓冲区 void read_device() { while (*buffer == 0) { // 等待设备写入数据 // 空循环 } printf("Data received: %c\n", *buffer); }volatile确保每次读取缓冲区都访问实际内存。 - 适用性:设备驱动、实时系统。
[!warning] 注意 在 POSIX 线程库中,互斥锁的实现通常包含内存屏障(memory barrier),这确保了锁保护的变量在锁释放和获取时从主内存同步更新。因此,线程总是能看到变量的的最新值,即使编译器进行了优化。
const 关注值的不可修改性,volatile 关注值的易变性,二者可组合使用:
restrict¶
用于限定指针为访问其指向数据的唯一途径,帮助编译器优化(如避免指针别名问题)。主要用途是:
- 函数参数中明确指针的独占性(如
memcpy的参数)。
void copy(int *restrict dest, const int *restrict src, int size) {
// 若无 restrict,编译器需假设 dest 和 src 可能重叠,无法优化为 memcpy
for (int i = 0; i < size; i++) dest[i] = src[i];
}
_Atomic¶
声明变量为原子类型,支持多线程环境下的无竞争访问。主要用途是:
- 多线程编程中保证操作的原子性(如自增、赋值)。
_Constexpr¶
用于表示函数或变量可以在编译期求值,相当于 C++ 中的 constexpr。
#include <stdio.h>
_Constexpr int square(int x) {
return x * x;
}
int main(void) {
// 编译期常量
_Constexpr int value = square(5);
// 也可以在运行期使用
int n = 6;
printf("square(%d) = %d\n", n, square(n));
return 0;
}
_Thread_local¶
用来表示变量是线程局部的,每个线程拥有变量的一个独立副本。
#include <stdio.h>
#include <pthread.h>
_Thread_local int thread_counter = 0;
void* thread_func(void* arg) {
for (int i = 0; i < 3; ++i) {
thread_counter++;
printf("Thread %ld: counter = %d\n", (long)arg, thread_counter);
}
return NULL;
}
int main(void) {
pthread_t t1, t2;
pthread_create(&t1, NULL, thread_func, (void*)1);
pthread_create(&t2, NULL, thread_func, (void*)2);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}
说明:
thread_counter每个线程都有自己的独立副本,互不干扰。- 在 C23 中也可以使用
thread_local(不带下划线)作为等效关键字。
| 修饰符 | 引入版本 | 功能 | 示例 | 注意事项 |
|---|---|---|---|---|
const |
C89 | 声明对象为只读,不可修改(除非通过指针绕过)。 | const int x = 5; |
声明时必须初始化,未初始化的 const 变量可能导致未定义行为。 |
volatile |
C89 | 禁止编译器优化,强制每次从内存读取值。 | volatile int *reg = 0x8000; |
常用于硬件操作或信号处理中的共享变量。 |
restrict |
C99 | 确保指针是访问其指向数据的唯一途径,允许编译器优化。 | void func(int *restrict a); |
违反此约束可能导致未定义行为(如指针别名)。 |
_Atomic |
C11 | 声明原子类型,支持多线程安全操作。 | _Atomic int count = 0; |
需包含 <stdatomic.h>,操作需使用原子函数(如 atomic_fetch_add)。 |
static |
K&R C(1978年之前) | 限定作用域为文件内,或使局部变量持久化。 | static int count = 0; |
静态局部变量只初始化一次,生命周期持续到程序结束。 |
extern |
K&R C(1978年之前) | 声明外部定义的变量或函数。 | extern int global_var; |
实际定义需在其他文件中,否则链接错误。 |
| _Constexpr | C23 | 表示变量或函数在编译时可求值,用于常量表达式。 | _Constexpr int value = square(5); |
某些编辑器可能不支持该关键字 |
| _Thread_local | C11 | 表示变量是线程局部的,每个线程有独立副本。也可写作 thread_local |
_Thread_local int thread_counter = 0; |
|
| 已弃用,用于建议编译器将变量存储在寄存器中(C11中不再强制支持)。 |
说明:
constvsvolatile:-
const关注值的不可修改性,volatile关注值的易变性,二者可组合使用: -
restrict的优化场景:
// 若无 restrict,编译器需假设 dest 和 src 可能重叠,无法优化为 memcpy
void copy(int *restrict dest, const int *restrict src, int size);
- 原子操作的必要性:
- 多线程中对非原子变量的并发操作(如
i++)可能引发数据竞争,需用_Atomic或互斥锁保护。
存储类型关键字¶
存储类别关键字 是用于指定变量存储方式和生命周期的关键词,主要包括 auto、register、static 和 extern。存类类型关键字属于类型修饰符中的一部分。
存储类别关键字 决定了变量的存储位置(如栈、静态存储区等)和存储方式(决定了生存时间),从而影响变量的 生命周期 和 作用域。
| 关键字 | 作用 |
|---|---|
auto |
默认(自动变量,C11中通常省略)。 |
static |
静态变量(文件作用域或块作用域内持久化)。 |
register |
建议编译器将变量存储在寄存器中(C11中不强制)。 |
extern |
声明外部变量(定义在其他文件或位置)。 |
比如我们可以通过static函数来限制函数的作用域和生命周期,从而提高代码的封装性和安全性。
- 作用域:
static函数的作用域仅限于定义它的文件(即当前的源文件)。其他文件无法访问或调用该函数。通过将函数声明为static,可以隐藏实现细节,防止其他文件直接调用该函数,从而提高代码的封装性和安全性。 - 生命周期:
static函数的生命周期与程序相同,其存储位置通常在静态存储区。
static 修饰的局部变量,其生命周期为整个程序,但作用域仍为块内。
常量¶
常量是程序中固定不变的值。常量的值在程序运行过程中不能被修改。常量的特性有:
- 常量的值在定义时确定,不能更改。
- 常量可以提高代码的可读性和可维护性。
字面常量(Literal Constants)¶
直接写在代码中的值,无标识符。字母常量分为整数常量、浮点数常量、字符常量,以及字符串常量四种。
字符串常量存储在只读内存区,不可修改。
整数常量¶
整数常量是表示整数值的字面量,用于在代码中直接表示整数。整数常量可以是十进制、八进制或十六进制形式,并且可以是无符号或长整数类型。
前缀与后缀规则¶
| 分类 | 符号 | 含义 | 示例 | 说明 |
|---|---|---|---|---|
| 前缀 | 无 | 十进制 | 123 |
默认十进制 |
0 |
八进制 | 077 (十进制63) |
以0开头(注意:0后必须跟0-7) |
|
0x 或 0X |
十六进制 | 0xFF (十进制255) |
以0x或0X开头,后跟0-9、A-F/a-f |
|
| 后缀 | 无 | 默认类型:int(十进制)、int/unsigned int(根据值大小) |
42 |
若值超出int范围,可能自动转为unsigned int或更大类型 |
u 或 U |
无符号类型(unsigned int) |
100U、0x1Fu |
可与l/ll组合(如100UL) |
|
l 或 L |
长整型(long int) |
123L、077L |
避免小写l(易与1混淆),建议用大写L |
|
ll 或 LL |
长长整型(long long int,C99引入) |
123LL、0x1A3BLL |
需C99及以上支持 | |
ul/lu等组合 |
组合指定无符号长整型(unsigned long)或更宽类型 |
123UL、0xABCDEFLLU |
顺序无关(如UL或LU等效),但需后缀连续(如ULL) |
关键规则
- 前缀优先级:
0开头为八进制,0x/0X开头为十六进制,否则为十进制。-
注意:
09是非法八进制(包含数字9)。 -
后缀组合:
- 允许组合使用(如
ULL表示unsigned long long)。 -
后缀不区分大小写,但建议大写以提高可读性(如
ULL优于ull)。 -
类型推断:
-
若无后缀,根据值和进制推断类型:
- 十进制:
int→long→long long(按值范围自动提升)。 - 八进制/十六进制:
int→unsigned int→long→unsigned long→long long等。
- 十进制:
-
常见错误:
0xl无效(十六进制需后跟有效数字,l是后缀而非数字)。123LU合法(等价于UL),但123UL更推荐。
示例:
int dec = 42; // 十进制int
int oct = 052; // 八进制42(十进制34)
int hex = 0x2A; // 十六进制2A(十进制42)
unsigned int u = 100U; // 无符号int
long l = 1234567890L; // 长整型
unsigned long ul = 9876543210UL; // 无符号长整型
long long ll = 123456789012345LL; // 长长整型
unsigned long long ull = 0xFFFFFFFFFFFFFFFFULL; // 无符号长长整型(64位全1)
浮点数常量¶
浮点数常量 是表示带有小数部分的数值的字面量,可以是十进制、科学计数法或十六进制形式。默认浮点常量是double,我们可以带有使用可选的后缀(如f、F、l、L)来指定其类型。
| 后缀 | 含义 | 示例 |
|---|---|---|
f |
表示float类型的浮点数常量 |
3.14f |
F |
表示float类型的浮点数常量 |
3.14F |
l |
表示long double类型的浮点数常量 |
3.14l |
L |
表示long double类型的浮点数常量 |
3.14L |
字符常量¶
字符常量指的是单引号 '' 包裹的单个字符,类型为 int(实际存储为 char 的整数值)。
字符常量本质是整数值(ASCII码),可直接参与整数运算:
字符常量默认是int类型,除⾮用前置L表⽰示wchar_t宽字符类型。
多字节字符集与宽字符¶
C语言默认使用单字节字符(ASCII),但可通过以下方式处理多字节字符(如中文)。
1. 多字节字符集(Multi-Byte Characters)
- 多字节字符集指的是多字节字符(如中文、日文)需占用多个
char存储单元(具体取决于编码方式,如UTF-8、GBK)。 - 例如,UTF-8编码的中文“中”占3字节:
0xE4 0xB8 0xAD。 -
使用
char[]数组或字符串字面量存储多字节字符序列:
2. 宽字符(Wide Characters)
- 使用
wchar_t类型(需包含<wchar.h>),表示宽字符(如Unicode字符)。 -
宽字符常量用
L''前缀表示: -
宽字符操作需使用宽字符函数(如
wprintf):
示例对比:
| 类型 | 示例 | 存储方式 | 适用场景 |
|---|---|---|---|
| 单字节字符 | char c = 'A'; |
1字节(ASCII) | 英文、数字、符号 |
| 多字节字符 | char s[] = "中文"; |
多个字节(如UTF-8的3字节/字) | 多语言混合字符串 |
| 宽字符 | wchar_t wc = L'中'; |
2或4字节(依赖实现) | Unicode字符统一处理 |
const 修饰的常量¶
声明为只读变量,不可修改(在C语言中不是真正的常量(不能用于数组长度声明),本质是变量,某些编译器可能允许绕过限制)。
枚举常量(Enum Constants)¶
通过 enum 定义一组整型常量。
宏常量(Macro Constants)¶
使用 #define 定义的文本替换常量(预处理阶段处理)。
示例:
#include <stdio.h>
#define PI 3.14 // 宏常量
const int MAX = 100; // const常量
int global_var = 10; // 全局变量(文件作用域)
void func() {
static int static_var = 0; // 静态局部变量
int local_var = 5; // 自动局部变量
static_var++;
printf("Static: %d, Local: %d\n", static_var, local_var);
}
int main() {
extern int global_var; // 声明外部全局变量
func(); // 输出:Static: 1, Local: 5
func(); // 输出:Static: 2, Local: 5
return 0;
}